Regression models offer a flexible and accurate approach to estimating salinity.
The simplest regression models can be represented graphically by curves passing through data on a TS scatter plot. For example the straight lines and parabolas fitted to data at interpolation levels within the non-overlapping 20-degree by 5-degree regions provide an easy visual representation of what regression models that are linear or quadratic function of temperature would predict for salinity to accompany measured temperature at that pressure level. Even simpler would be to fit a constant to the model, modeling salinity by the mean of the training data in order to estimate salinity by its climatological mean, which could be represented by a vertical (temperature independent) line through the center of the data. While it is simple to add other regressors like longitude and/or latitude to the model (and color-coding the data on the scatter plots indicate that such regressors should be useful) representing the model graphically on a two-dimensional plot is no longer possible.
While models are computed independently at each pressure level with nothing to guarantee that models at adjacent levels are similar, because the ocean generally does not change abruptly suggests that the models should be similar. Plots of the coefficients plotted vs. pressure level shows this to be the case, both for salinity as a linear or quadratic functions of temperature and for linear functions of temperature and longitude or latitude.
Judging how well a model might perform for independent data from how well it approximates the data to which it has been fitted is difficult, because the new data might encompass variability that was not encountered in the training data, and that difficulty increases with the number of regressors. Nevertheless, the root-mean-square residual (difference between the training value and its model estimate) can give an optimistic estimate of the model's accuracy.
When fitting the regression model to the training data it is possible to determine, along with the coefficients of the various regressors, estimates of the uncertainty of the coefficients. The uncertainty can be expressed as a t statistic for each regressor; when the probability of encountering a greater t value is small, the corresponding regressor's inclusion in the model is justified. For models based on temperature and longitude or latitude, probability for encountering a larger t value for the coefficient of the term proportional to temperature can be a sizable near the salinity minimum. When the regressor is not justified, it might be dropped to give a more robust model. When modeling oceanic data it is reasonable to expect that some regressors migh be more important in some regions or at some levels and less important at others.
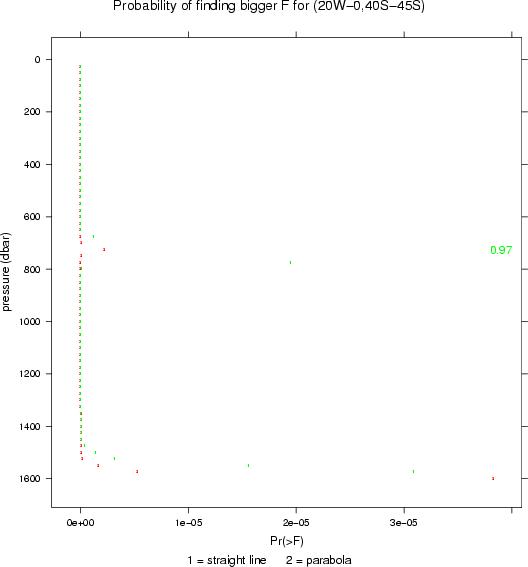
The overal quality of a fitted model can be assessed by the F statistic. The probability of finding observations giving a larger F value for salinity as linear and quadratic functions of temperature at each level can be seen for the southwest-most 20x5 sub-region. Note the large probabilities are found at the salinity minimum (725 dbar) and below 1500 dbar.
Stepwise regression is a procedure for considering all possible combinations of regressors and using something like Akaike' information criterion (AIC) to choose which to retain and which to drop. Which regressors are chosen varies from sub-region to sub-region and from level to level within a given subregion. To get an overview of which models are selected when temperature, temperature squared, longitude, and latitude are the possible regressors, it is possible to plot the probabilities for encountering larger t values for each regressor at each level for each sub-region, plotting nothing when the corresponding regressor is dropped.
{kind=link}