A Single-Sample Estimate of Shrinkage in Meteorological
Forecasting
Weather and Forecasting: (1997), 12, 847-858
Paul W. Mielke Jr. *Department
of Statistics, Colorado State University, Fort Collins, Colorado
Kenneth J. Berry Department of Sociology, Colorado State University,
Fort Collins, Colorado
Christopher W. Landsea*NOAA Climate
and Global Change Fellowship, NOAA/AOML/Hurricane Research Division, Miami,
Florida
William M. Gray Department of Atmospheric Science, Colorado State
University, Fort Collins, Colorado
AMS Copyright Notice © Copyright 1997 American Meteorological
Society (AMS). Permission to use figures, tables, and brief excerpts from
this work in scientific and educational works is hereby granted provided
that the source is acknowledged. Any use of material in this work that is
determined to be "fair use" under Section 107 or that satisfies the conditions
specified in Section 108 of the U.S. Copyright Law (17 USC, as revised by
P.L. 94-553) does not require the Society's permission. Republication, systematic
reproduction, posting in electronic form on servers, or other uses of this
material, except as exempted by the above statements, requires written permission
or license from the AMS. Additional details are provided in the AMS Copyright
Policies, available from the AMS at 617-227-2425 or amspubs@ametsoc.org.
Permission to place a copy of this work on this server has been provided
by the AMS. The AMS does not guarantee that the copy provided here is an
accurate copy of the published work.
ABSTRACT
 An
estimator of shrinkage based on information contained in a single sample
is presented and the results of a simulation study are reported. The effects
of sample size, amount, and severity of nonrepresentative data in the population,
inclusion of noninformative predictors, and least (sum of) absolute deviations
and least (sum of) squared deviations regression models are examined on
the estimator. A single-sample estimator of shrinkage based on drop-one
cross-validation is shown to be highly accurate under a wide variety of
research conditions.
An
estimator of shrinkage based on information contained in a single sample
is presented and the results of a simulation study are reported. The effects
of sample size, amount, and severity of nonrepresentative data in the population,
inclusion of noninformative predictors, and least (sum of) absolute deviations
and least (sum of) squared deviations regression models are examined on
the estimator. A single-sample estimator of shrinkage based on drop-one
cross-validation is shown to be highly accurate under a wide variety of
research conditions.
1. Introduction
Meteorologists
have long recognized the importance of accurately quantifying statistical
forecast skill. One of the primary tools of meteorological forecasting
is multiple regression analysis (Murphy and Winkler 1984
)
where, given data on a response variable yi and associated
predictor variables xij, where j = 1, . ..,
p;i
= 1, ...,
n;
p
denotes the number of predictors; and n represents the number of
events; the goal is to find some function of the xij
values that is an accurate and precise predictor of yi.
It is generally recognized that any estimate of forecast skill grounded
in a multiple regression model that is based on a sample of observations
is characteristically higher than the forecast skill that would be obtained
from a multiple regression model that is based on the entire population
of observations (Mosteller and Tukey 1977 ; Picard
and Cook 1984 ; Michaelsen 1987 ; Barnston
and Van den Dool 1993 ). It is also widely accepted that the fit of
the multiple regression model to new sample data is nearly always less
precise than the fit of the same multiple regression model to the original
sample data on which the model was based. This is reflected in lower forecast
skill levels obtained when sample-based multiple regression models are
used to predict future events.
..,
p;i
= 1, ...,
n;
p
denotes the number of predictors; and n represents the number of
events; the goal is to find some function of the xij
values that is an accurate and precise predictor of yi.
It is generally recognized that any estimate of forecast skill grounded
in a multiple regression model that is based on a sample of observations
is characteristically higher than the forecast skill that would be obtained
from a multiple regression model that is based on the entire population
of observations (Mosteller and Tukey 1977 ; Picard
and Cook 1984 ; Michaelsen 1987 ; Barnston
and Van den Dool 1993 ). It is also widely accepted that the fit of
the multiple regression model to new sample data is nearly always less
precise than the fit of the same multiple regression model to the original
sample data on which the model was based. This is reflected in lower forecast
skill levels obtained when sample-based multiple regression models are
used to predict future events.
It is useful
to have elementary terms to distinguish between the fit of a multiple regression
model to the sample data on which the model has been determined and the
fit of the same multiple regression model to an independent sample of data.
The former is termed retrospective fit and the latter is termed validation
fit (Copas 1983 ). The term shrinkage denotes the
drop in skill from retrospective fit to validation fit (Copas
1983 ) and indicates how useful the sample-based regression coefficients
will be for prediction on other datasets. For purposes of clarification,
shrinkage involves the following four-step procedure. First, a multiple
regression model is fit to a sample dataset by optimizing the regression
coefficients relative to a fitting criterion, for example, least squares.
Second, the goodness of fit of the multiple regression model is measured
by an index, such as a squared multiple correlation coefficient. Third,
the obtained multiple regression model is applied to an independent sample
dataset and a second goodness-of-fit index is obtained for the independent
dataset. Fourth, a ratio of the two indices is constructed where the goodness-of-fit
index from the original dataset is the denominator. This ratio is termed
shrinkage since it is usually less than unity.
Mielke
et al. (1996) investigated the effects of sample size, type of regression
model, and noise-to-signal ratio on the degree of shrinkage in five populations
that differed in the amount and degree of contaminated data. Shrinkage
was defined as the ratio of the validation fit of a sample regression equation
to the retrospective fit of the same sample regression equation where the
validation fit was assessed on five independent samples, averaged over
10000 simulations. While this index of shrinkage is both rigorous and comprehensive,
the use of six independent samples precludes its use in routine research
situations. In this paper, an estimate of shrinkage is developed that is
based on a single sample and can easily be employed by research meteorologists.
Comparisons with the index of shrinkage given by Mielke
et al. (1996) indicate that the single-sample estimate of shrinkage
is very accurate under a wide variety of conditions. The single-sample
estimate of shrinkage is related to cross-validation methods that have
become standard for assessing the predictive validity of forecast skill.
2. Cross-validation
Historically,
users of multiple regression procedures have developed methods to assess
how accurately sample regression coefficients estimate the corresponding
population regression coefficients. The usual procedure is to test the
sample regression coefficients on an independent set of sample data. This
practice has come to be known as cross-validation. A comprehensive historical
background on cross-validation is provided by Stone (1974
, 1978) , Geisser (1975) ,
Mosteller
and Tukey (1977) , and Snee (1977) . Camstra
and Boomsma (1992) present an extensive overview of the use of cross-validation
in regression, where the emphasis is on the prediction of individual observations,
and in covariance structure analysis, where the emphasis is on future values
of variances and covariances. Michaelsen (1987)
and Elsner and Schmertmann (1994) describe and discuss
cross-validation methods as they pertain to meteorological forecasting.
It is widely
recognized that to be useful, any sample regression equation must hold
for data other than those on which the regression equation was developed.
When sample data are used to determine the regression coefficients that
best predict the response variable from the set of predictor variables,
assuming that the variables to be used in the regression equation have
already been selected, prediction performance is usually overestimated
(Picard and Cook 1984). Because the sample regression
coefficients are determined by an optimizing process that is conditioned
on the sample data, the regression equation generally provides better predictions
for the sample data on which it is based than for any other dataset. This
is sometimes referred to as testing on the training data (Glick
1978). It should be noted that the use of cross-validation precludes
any manipulation of the dataset prior to the development of the regression
model and subsequent cross-validation.
In general,
cross-validation consists of determining the regression coefficients in
one sample and applying the obtained coefficients to the predictor scores
of another sample. The initial sample is termed the calibration or training
sample and the second sample is called the validation or test sample
(Browne 1975a ,b
; Huberty et al. 1987 ; Camstra
and Boomsma 1992 ; MacCallum et al. 1994).
The calibration sample is used to calculate the regression coefficients,
and the predictive validity of the fitted equation is verified on the validation
sample.
As defined,
cross-validation requires two samples. Because a second sample is often
not readily available, an alternative approach is often used in which a
large sample is randomly split into two subsamples. One subsample is specified
as the calibration sample and the second sample is designated the validation
sample. The many problems associated with this approach to cross- validation
are summarized in Lachenbruch and Mickey (1968)
, Picard and Cook (1984) , and Picard
and Berk (1990) . Setting aside the obvious loss of information in
splitting samples (Browne and Cudeck 1992 ),
a significant problem is the difficulty in procuring large samples, which
are not available in many research situations. In addition, when calibration
sample sizes are small, the regression coefficients are less precise than
those that would be obtained if the entire sample had been used (Horst
1966 ). Mosier (1951) suggested a double cross-validation
procedure where the regression coefficients are calculated for both the
calibration and validation samples and the two regression equations are
cross-validated on the sample that was not used to establish the regression
coefficients. Questions have been raised as to exactly what should be done
when the results of the two cross-validations differ (Snee
1977 ). It has been suggested that if the two sets of regression coefficients
are not too different, then a new set of coefficients may be obtained from
the combined calibration and validation samples (Mosier
1951 ). While no estimate of predictive validity is available for the
combined sample, Mosier (1951) posited that it may
be approximated by the average of the predictive validities obtained for
the original calibration and validation samples.
Cross-validation
is certainly not limited to just two samples. The data can be divided into
more than two samples and multiple cross-validations can be obtained. Multiple
cross-validation involves partitioning an available sample of size n
into a calibration sample of size n k
and a validation sample of size k. The cross- validation procedure
is realized by withholding each validation sample of size k, calculating
a regression model from the remaining calibration sample of size nk,
and validating each of the (nk) possible regression
models on the remaining sample of size k held in reserve. Since
k
= 1 requires validating only n regression models on the remaining
sample of size 1 held in reserve, this special case is both easily implemented
and commonly used. In various literature, the case where k = 1 is
termed drop-one cross-validation, leave-one-out cross-validation, hold-one-out
cross-validation, or the U method. Stone (1978)
provides a thorough review of drop-one cross-validation. Drop-one cross-validation
is an exhaustive method involving substantial redundancy in the participation
of each data point (far more redundancy when k > 1). However, the
exhaustive features of drop-one cross-validation may provide a comprehensive
evaluation of predictive accuracy and a solid estimate of predictive skill
(Barnston and Van den Dool 1993 ).
k
and a validation sample of size k. The cross- validation procedure
is realized by withholding each validation sample of size k, calculating
a regression model from the remaining calibration sample of size nk,
and validating each of the (nk) possible regression
models on the remaining sample of size k held in reserve. Since
k
= 1 requires validating only n regression models on the remaining
sample of size 1 held in reserve, this special case is both easily implemented
and commonly used. In various literature, the case where k = 1 is
termed drop-one cross-validation, leave-one-out cross-validation, hold-one-out
cross-validation, or the U method. Stone (1978)
provides a thorough review of drop-one cross-validation. Drop-one cross-validation
is an exhaustive method involving substantial redundancy in the participation
of each data point (far more redundancy when k > 1). However, the
exhaustive features of drop-one cross-validation may provide a comprehensive
evaluation of predictive accuracy and a solid estimate of predictive skill
(Barnston and Van den Dool 1993 ).
Drop-one cross-validation
is usually credited to Lachenbruch (1967) or
Lachenbruch
and Mickey (1968) . However, Toussaint (1974)
has traced the drop-one method to earlier sources under different names
(Glick 1978 ). Currently, the drop-one method is the
cross-validation procedure of choice and it is not unusual to see the term
cross-validation virtually equated with the drop-one method (e.g.,
Nicholls
1985 ; Livezey et al. 1990 ).
For many researchers,
the method of choice for cross- validation is to create a model on one
sample and test the model on a second sample drawn from the same population;
alternatively, a model is created on a substantial portion of a sample
and tested on the remaining portion of the sample. In either case, the
selection of predictors can be based on information in the population or
some other out-of-sample source, or the selection of predictors can involve
subset selection based on in-sample information. In addition, the regression
coefficients are nearly always based on information in the calibration
sample. Much of the early work in cross-validation specifically limited
analyses to fixed models where the number and variety of predictors is
determined a priori and not based on subset selection (e.g., Browne
1975a , 1975b ; Camstra
and Boomsma 1992 ; MacCallum et al. 1994 ).
Thus, cross-validation in this context implies validation of the sample
regression coefficients only. In those cases where subset selection is
based on the sample information, cross-validation implies validation of
the subset selection process and the sample regression coefficients.
The advent
of double cross-validation brought additional complications. Given fixed
predictors, the regression coefficients from each sample are tested on
the other sample and any differences can be consolidated by some form of
weighted averaging of the regression coefficients (Subrahmanyam
1972 ). However, given sample-based subset selection, there is the
added complication that each sample will select a different number and/or
a different set of predictors. It is much more difficult to resolve discrepancies
between the two sample validation results. Browne
(1970) provides results of random sampling experiments demonstrating
the effects of not fixing the predictors beforehand. With drop- one cross-validation
it is possible to conceive of up to n different but overlapping
sets of predictors and up to
n different values for the regression
coefficients for each predictor. The satisfactory and optimal combining
of these differences appears very difficult; see, for example, Browne
and Cudeck (1989) and MacCallum et al. (1994)
.
Cross-validation
is not without its critics and there is evidence that suggests some possible
drawbacks to drop-one cross-validation. Glick (1978)
and Hora and Wilcox (1982) provide simulation studies
of drop-one cross-validation in discriminant analysis. Both studies indicate
that the estimates have relatively high variability over repeated sampling,
possibly due to the repeated use of the original data. The results of both
Glick
(1978) and Hora and Wilcox (1982) were based on
discriminant analysis, which has a binary error function.
Efron
(1983) notes that cross-validation performs somewhat better given a
smooth residual sum of squares error function. Finally, some investigators
note that a model that fits the validation sample as well as the calibration
sample is not necessarily a validated model. Maltz (1994)
, for example, argues that cross-validation may only show that the procedure
used to split the sample did, in fact, divide the sample into two similar
subgroups.
If a specific
sample dataset exhibits a high first-order autoregressive pattern, drop-one
cross-validation may overestimate the validation fit. For example, if a
single sample consists of cases selected from a time series, then the cases
in a given cycle (e.g., a month, a year, or a decade) may be highly correlated.
In such cases a drop-k cross-validation may be required to mitigate
the cyclic pattern, where k exceeds the length of the cycle. Michaelsen
(1987) has researched the effects of autoregressive effects on cross-validation
in statistical climate forecast models.
3. Statistical measures
Let the population
and sample sizes be denoted by N and n, respectively, let
yi
denote the response variable, and let xi1,
...,
xip
denote the p predictor variables associated with the ith
of n events. Consider the linear regression model given by
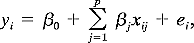 where
where 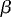 0, ..., p
are p + 1 unknown parameters and ei is the error
term associated with the ith of n events. Two types of regression
models are of interest: least (sum of) absolute deviations (LAD) regression
models and least (sum of) squared deviations (LSD) regression models. The
LAD and LSD prediction equations are given by
0, ..., p
are p + 1 unknown parameters and ei is the error
term associated with the ith of n events. Two types of regression
models are of interest: least (sum of) absolute deviations (LAD) regression
models and least (sum of) squared deviations (LSD) regression models. The
LAD and LSD prediction equations are given by
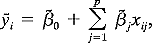 where
where 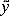 i is the
predicted value of yi and
i is the
predicted value of yi and 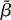 0,
..., p
minimize the expression
0,
..., p
minimize the expression
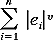 with v = 1 and v = 2 associated with the LAD and LSD regression
models, respectively.
with v = 1 and v = 2 associated with the LAD and LSD regression
models, respectively.
A measure of
agreement is employed to determine the correspondence between the yi
and i values, for
i
= 1, ...,
n.
Many researchers have utilized measures of agreement in assessing prediction
accuracy, for example, Willmott (1982) , Willmott
et al. (1985) , Kelly et al. (1989) , Tucker
et al. (1989) , Gray et al. (1992) , McCabe
and Legates (1992) , Badescu (1993) , Elsner
and Schmertmann (1993) , Hess and Elsner (1994)
, Cotton et al. (1994) , and Lee et
al. (1995) . Watterson (1996) provides a comprehensive
comparison of various measures of agreement.
In this simulation
study, the measure of agreement for both the LAD and LSD prediction equations
is given by
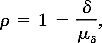 where
where
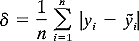 and
and 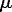
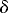 is the average value of over all
n!
equally likely permutations of y1, ...,
yn
relative to 1, ..., n
under the null hypothesis that the n pairs (yi
and i for i
= 1, ...,
n)
are merely the result of random assignment. This reduces to the simple
computational form given by
is the average value of over all
n!
equally likely permutations of y1, ...,
yn
relative to 1, ..., n
under the null hypothesis that the n pairs (yi
and i for i
= 1, ...,
n)
are merely the result of random assignment. This reduces to the simple
computational form given by
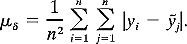 Since
Since 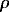 is a chance-corrected measure
of agreement, = 1.0 implies that all
paired values of yi and i
for i = 1, ...,
n
fall on a line with unit slope that passes through the origin (i.e., a
perfect forecast). The choice of rather
than the Pearson productmoment correlation coefficient (r) or r2
(the coefficient of determination) is that the latter are measures of linearity
and not measures of agreement. Also, the choice of the mean absolute error
for rather than the mean squared
error is that extreme values influence the squared Euclidean differences
of the MSE far more than the Euclidean differences of the MAE. These choices
are elaborated by Mielke et al. (1996) .
is a chance-corrected measure
of agreement, = 1.0 implies that all
paired values of yi and i
for i = 1, ...,
n
fall on a line with unit slope that passes through the origin (i.e., a
perfect forecast). The choice of rather
than the Pearson productmoment correlation coefficient (r) or r2
(the coefficient of determination) is that the latter are measures of linearity
and not measures of agreement. Also, the choice of the mean absolute error
for rather than the mean squared
error is that extreme values influence the squared Euclidean differences
of the MSE far more than the Euclidean differences of the MAE. These choices
are elaborated by Mielke et al. (1996) .
4. Data and simulation procedures
The present study
investigates the accuracy and utility of a single-sample estimator of shrinkage.
Also considered are the effects of sample size, type of regression model (LAD
and LSD), and noise-to-signal ratio in five populations that differ in amount
and degree of contaminated data. Sample sizes (n) of 15, 25, 40, 65,
100, 160, 250, and 500 events are obtained from a fixed population of N
= 3958 events, which, for the purpose of this study, is not contaminated with
extreme cases; a fixed population of N = 3998 events consisting of the
initial population and 40 moderately extreme events (1% moderate contamination);
a fixed population of N = 3998 events consisting of the initial population
and 40 very extreme events
(1% severe contamination); a fixed population of N = 4158 events
consisting of the initial population and 200 moderately extreme events (5% moderate
contamination); and a fixed population of N = 4158 events consisting
of the initial population and 200 very extreme events (5% severe contamination).
The 3958 available primary events used to construct each of the five populations
used in this study consist of a response variable and p = 10 predictor
variables. Specifics of the meteorological data used to construct these five
populations are given in Mielke et al. (1996) .
Two prediction models
are considered for each of the five populations. The first prediction model
(case 10) consists of p = 10 independent
variables, and the second prediction model (case 6) consists of p = 6
independent variables. In case 10, 4 of the 10 independent variables in the
initial population of N = 3958 events were found to contribute no information
to the predictions. Case 6 is merely the prediction model with the four noninformative
independent variables of case 10 deleted. Both the case 10 and case 6 prediction
models were constructed from the initial fixed population of N = 3958
events. The reason for the two prediction models is to examine the effect of
including noninformative independent variables (i.e., noise) in a prediction
model.
5. Findings and discussion
The results
of the study are summarized in Tables 1,
2,
3, 4,
5.
In Tables 1,
2,
3, 4,
5,
each row is specified by 1) a sample size (n), 2) p = 10
(case 10) and p = 6 (case 6) independent samples, and 3) LAD and
LSD regression analyses. In each of the five tables the first column (C1)
contains the true values for the designated
population and the second column (C2) contains the average of 10000 randomly
obtained sample estimates of ,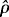 ,
where the values are based on the
sample regression coefficients for each of the 10000 independent samples,
that is, a measure of retrospective fit. The third column (C3) measures
the effectiveness of validating sample regression coefficients. In this
column the sample regression coefficients from 10000 random samples were
first obtained from column C2, then for each of these 10000 sets of sample
regression coefficients an additional five independent random samples of
the same size (n = 15, ...,
500) were drawn from the population. The sample regression coefficients
from C2 were then applied to each of the five new samples, and
values were computed for each of these five samples for a total of 50000
values. The average of the 50000
values is reported in column C3, yielding a measure of validation fit.
The fourth column (C4) contains the average of 10000 randomly obtained
drop-one sample values where each
of the values is based on the same
sample data that yields one of the 10000 sample
values composing the averages in column C2. Thus, each value in column
C4 represents the average of n times 10000
values. The fifth column (C3/C2) contains the ratio of the average
value of C3 to the corresponding
value of C2, that is, the index of shrinkage. The sixth column (C4/C2)
contains the ratio of the average
value of C4 to the average value
of C2, that is, the drop-one single- sample estimator of shrinkage, as
measured by C3/C2. The seventh column (C4/C3) contains the ratio of the
average value of C4/C2 to the average
value of C3/C2, that is, the ratio of the drop-one single-sample estimator
of shrinkage to the index of shrinkage. The eighth column (C3/C1) contains
the ratio of the validation fit of C3 to the corresponding true fit, measured
by the population value given in C1.
The values of columns C1, C2, C3, C3/C2, and C3/C1 are contained in Mielke
et al. (1996) .
,
where the values are based on the
sample regression coefficients for each of the 10000 independent samples,
that is, a measure of retrospective fit. The third column (C3) measures
the effectiveness of validating sample regression coefficients. In this
column the sample regression coefficients from 10000 random samples were
first obtained from column C2, then for each of these 10000 sets of sample
regression coefficients an additional five independent random samples of
the same size (n = 15, ...,
500) were drawn from the population. The sample regression coefficients
from C2 were then applied to each of the five new samples, and
values were computed for each of these five samples for a total of 50000
values. The average of the 50000
values is reported in column C3, yielding a measure of validation fit.
The fourth column (C4) contains the average of 10000 randomly obtained
drop-one sample values where each
of the values is based on the same
sample data that yields one of the 10000 sample
values composing the averages in column C2. Thus, each value in column
C4 represents the average of n times 10000
values. The fifth column (C3/C2) contains the ratio of the average
value of C3 to the corresponding
value of C2, that is, the index of shrinkage. The sixth column (C4/C2)
contains the ratio of the average
value of C4 to the average value
of C2, that is, the drop-one single- sample estimator of shrinkage, as
measured by C3/C2. The seventh column (C4/C3) contains the ratio of the
average value of C4/C2 to the average
value of C3/C2, that is, the ratio of the drop-one single-sample estimator
of shrinkage to the index of shrinkage. The eighth column (C3/C1) contains
the ratio of the validation fit of C3 to the corresponding true fit, measured
by the population value given in C1.
The values of columns C1, C2, C3, C3/C2, and C3/C1 are contained in Mielke
et al. (1996) .
It should be
noted in this context that both C3 and C4 are free from any selection bias.
Selection bias occurs when a subset of predictor variables is selected
from the full set of predictor variables in the population based on information
contained in the sample. In this study, selection bias has been controlled
by selecting the two sets of predictor variables (i.e., cases 10 and 6)
from information contained in the population and not from information contained
in any sample. Specifically, in the case of C3, the predictor variables
were selected from information in the population, the regression coefficients
were based on information contained in the sample for these (10 or 6) predetermined
predictor variables, then the regression coefficients were applied to five
new independent samples of the same size and drawn from the same population.
This process was repeated for 10000 samples, producing 50000
values. Each C3 value is an average of these 50000
values. Thus, while there is an optimizing bias due to retrospective fit,
there is no selection bias. In the case of C4, the predictor variables
were again selected from information contained in the population and the
regression coefficients were based on information contained in the sample,
after dropping one observation. A
value was calculated on the set of n
1 y and values, and the procedure
was repeated n times, dropping a different observation each time.
The entire process was repeated for 10000 samples, producing n times
10000 values. Each C4 value is
an average of these n times 10000
values. Thus, there is no selection bias. The advantage to this approach
is that the optimizing bias can be isolated and examined while the selection
bias is controlled. In addition, this approach is more conservative as
validation fit is almost always better when subset selection is included
(MacCallum et al. 1994 ). The drawback to this approach is that the results
cannot be generalized to studies that selected both prediction variables
and regression coefficients based on sample information and, in addition,
shrinkage may be increased.
The ratio values
in column C3/C2 in Tables 1, 2,
3,
4, 5 provide
a comprehensive index of shrinkage that serves as a benchmark against which
the accuracy of the drop- one single-sample estimator of shrinkage given
in column C4/C2 can be measured. The ratio values in column C4/C3 were
obtained by dividing the ratio values in column C4/C2 by the corresponding
ratio values in column C3/C2. They provide the comparison ratio values
by which the drop-one single-sample estimator of shrinkage is evaluated.
For each of
the five populations summarized in Tables 1,
2,
3, 4,
5,
the ratio values in column C4/C3 are close to unity for samples with n
> 25. The few C4/C3 values that exceed 1.0 are probably due to sampling
error. It should be noted that the C4/C3 ratios tend to be less than unity
for the smaller sample sizes. When n 25, reductions from unity of the C4/C3 values are 4.5%11% for the LAD
regression model and 4.5%15% for the LSD regression model in population
1. For populations 25, the corresponding reductions are 4%10% (LAD) and
4.5%14% (LSD), 3.5%9.5% (LAD) and 3.5%14% (LSD), 3%6% (LAD) and 4.5%11%
(LSD), and 0%5.5% (LAD) and 0%11% (LSD), respectively. Thus, the drop-one
single-sample estimator (i.e., C4/C2) is an excellent estimator of shrinkage
(i.e., C3/C2), although it is conservative for very small samples. This
conclusion holds for all sample sizes greater than n = 25, both
cases (6 and 10), both regression models (LAD and LSD), and all five populations
with differing degrees and amounts of data contamination.
25, reductions from unity of the C4/C3 values are 4.5%11% for the LAD
regression model and 4.5%15% for the LSD regression model in population
1. For populations 25, the corresponding reductions are 4%10% (LAD) and
4.5%14% (LSD), 3.5%9.5% (LAD) and 3.5%14% (LSD), 3%6% (LAD) and 4.5%11%
(LSD), and 0%5.5% (LAD) and 0%11% (LSD), respectively. Thus, the drop-one
single-sample estimator (i.e., C4/C2) is an excellent estimator of shrinkage
(i.e., C3/C2), although it is conservative for very small samples. This
conclusion holds for all sample sizes greater than n = 25, both
cases (6 and 10), both regression models (LAD and LSD), and all five populations
with differing degrees and amounts of data contamination.
Column C3/C1
summarizes, in ratio format, the validation fit (C3) to the true population
value (C1). This is sometimes referred to as expected skill (Mielke et
al. 1996 ). In general, the C3/C1 values indicate the amount of skill that
is expected relative to the true skill possible when an entire population
is available. More specifically, the C3/C1 values indicate the expected
reduction in fit of the y and
values for future events (Mielke et al. 1996 ). A C3/C1 value that is greater
than 1.0 is cause for concern since this indicates that the sample regression
coefficients provide a better validation fit, on the average, than would
have been possible had the actual population been available.
Inspection
of column C3/C1 in Table 1 reveals that
the LSD regression model consistently performs better than the LAD regression
model, case 10 has lower values than case 6, and the C3/C1 values increase
with increasing sample size. Table 2, with
1% moderate contamination, yields a few C3/C1 values greater than 1.0 and
they all appear with the LSD regression model.
Table 3, with 1% severe contamination, shows the same pattern, but
the C3/C1 ratio values are somewhat higher. Table
4, with 5% moderate contamination, continues the same motif and Table
5, with 5% severe contamination, contains C3/C1 values considerably
greater than 1.0 for nearly every case. It is abundantly clear that with
only a small amount of moderate or severe contamination, the LSD regression
model produces inflated estimates of expected skill. The LAD regression
model, based on absolute deviations about the median, is relatively unaffected
by even 1% severe contamination, but the LSD regression model, based on
squared deviations about the mean, systematically overestimates the validation
fit and yields inflated values of expected skill (i.e., C3/C1).
Since C3 (validation
fit ) values and C4 (drop-one single-sample
validation fit ) values are essentially
the same for all five populations, both cases, both regression models,
and all sample sizes, it is readily apparent that C4/C1 ratios would be
nearly identical to the C3/C1 ratios in Tables
1, 2, 3,
4, 5. Consequently,
caution should be exercised in using drop-one estimators with the LSD regression
model as they will likely provide inflated estimates of validation fit
when contaminated data are present. Because the drop-one estimate of shrinkage
is equivalent to drop- one cross-validation, the same caution applies to
drop-one cross-validation with an LSD regression model.
While it is
abundantly evident that LSD regression systematically overestimates validation
fit, the reason for the optimistic C3/C1 values is not as manifest. It
is obvious that the inflated estimates of expected skill for LSD regression
in Tables 1, 2,
3, 4, 5
are systematically related to sample size with larger sample sizes associated
with C3/C1 values in excess of 1.0. This is probably due to a moderately
or severely contaminated population event occurring in a single sample.
Very small samples (e.g., n = 15) are not likely to include a contaminated
event, whereas very large samples (e.g., n = 500) are much more
likely to include one or more contaminated events. Table
6 provides the probability values that no contaminated population event
belongs to a single sample for both 1% and 5% contamination. The probability
that no contaminated event belongs to a single sample with 1% moderate
or severe contamination in the population is given by (3958/3998)n,
and the probability that no contaminated event belongs to a single sample
with 5% moderate or severe contamination in the population is given by
(3958/4158)n in Table
6. For 1% moderate or severe contamination, the probability of selecting
no contaminated events from the population is greater than 0.50 for samples
of size n 65. For 5% moderate or severe
contamination, the probability of selecting no contaminated events from
the population never exceeds 0.50. Given the well-known sensitivity of
LSD regression to extreme events, it is not surprising that LSD regression
yields optimistic levels of expected skill for larger samples that are
more likely to contain one or more moderate or severely contaminated events.
It should be noted in Table 5 that neither
LSD nor LAD regression is able to accommodate 5% severe contamination.
The single
sample estimate of shrinkage, C4, is higher for 6 predictors than for 10
predictors in Table 1 with LAD regression
and n 160 and with LSD regression and
n 250, in
Table
2 with LAD regression and n 250,
and with LSD regression and n 40. The
same relationship holds for both LAD and LSD regression in Table
3 with n 40 and in Tables 4
and 5 with n
25. These results are consistent with the influence of contamination since
when n is small, the influence of additional noninformative predictors
is mitigated because the probability of selecting a contaminated event
in each sample is reduced. Clearly, regression models containing noninformative
predictors should be avoided (Browne and Cudeck 1992 ).
The standard
deviations of the 10000 values
composing C2, SD(|C2), and the standard
deviations of the 10000 drop-one
values composing C4, SD(|C4), are given
for each sample size (n = 15, ...,
500), case (10 and 6 predictors), and regression model (LAD and LSD) combination
in Tables 7,
8,
9,
10,
and 11, which correspond to the five contamination
levels of Tables 1, 2,
3, 4, 5
, respectively. In particular,
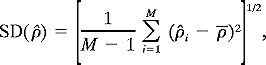 where
where
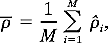 M = 10000 in this study, and
M = 10000 in this study, and 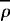 corresponds to either C2 or C4. The standard deviations are confined to SD(|C2)
and SD (|C4) since the
associated estimable single sample values
exist only for C2 and C4. For all five tables, SD(|C2)
is smaller than SD(|C4) for small sample sizes.
However, SD(|C2) and SD(|C4)
become more similar to one another with increasing sample sizes. Also for all
five tables, the SD(|C2) values are fairly
similar for cases with 10 and 6 predictors; this also holds for the SD(|C4)
values. The differences between LAD and LSD regression for both SD(|C2)
and SD(|C4) are more complex. While SD(|C2)
is smaller for LAD regression than for LSD regression with small sample sizes
(15, 25, and 40), the SD(|C2) and SD(|C4)
values are larger (perhaps slightly) for LAD regression than for LSD regression
in Table 7. In Tables 8
and 9, SD(|C2)
is smaller for LAD regression than for LSD regression whereas this observation
holds for SD(|C4) only with large sample sizes
(250 and 500). In Tables 10 and 11,
except for SD(|C2) with small sample sizes
(15, 25, and 40), both SD(|C2) and SD(|C4)
are larger for LAD regression than for LSD regression.
corresponds to either C2 or C4. The standard deviations are confined to SD(|C2)
and SD (|C4) since the
associated estimable single sample values
exist only for C2 and C4. For all five tables, SD(|C2)
is smaller than SD(|C4) for small sample sizes.
However, SD(|C2) and SD(|C4)
become more similar to one another with increasing sample sizes. Also for all
five tables, the SD(|C2) values are fairly
similar for cases with 10 and 6 predictors; this also holds for the SD(|C4)
values. The differences between LAD and LSD regression for both SD(|C2)
and SD(|C4) are more complex. While SD(|C2)
is smaller for LAD regression than for LSD regression with small sample sizes
(15, 25, and 40), the SD(|C2) and SD(|C4)
values are larger (perhaps slightly) for LAD regression than for LSD regression
in Table 7. In Tables 8
and 9, SD(|C2)
is smaller for LAD regression than for LSD regression whereas this observation
holds for SD(|C4) only with large sample sizes
(250 and 500). In Tables 10 and 11,
except for SD(|C2) with small sample sizes
(15, 25, and 40), both SD(|C2) and SD(|C4)
are larger for LAD regression than for LSD regression.
6. Summary
Mielke
et al. (1996) investigated the effects of sample size, type of regression
model, and noise-to-signal ratio on the degree of shrinkage in five populations
containing varying amounts and degrees of data contamination. Shrinkage
was measured as the ratio of the validation fit of a sample-based regression
model to the retrospective fit of the same regression model where the validation
fit was assessed on five independent samples from the same population.
While the Mielke et al. (1996) index of shrinkage
is both rigorous and comprehensive, it involves an additional five independent
samples and thus is not useful in routine applications. In this paper a
drop-one single-sample estimator of shrinkage is developed and evaluated
on the same dataset used by Mielke et al. (1996)
. The drop-one single-sample estimator provides an accurate estimate of
shrinkage for the five populations, both regression models, both cases,
and all sample sizes, although the estimator is slightly conservative for
very small sample sizes.
Finally, a
caution is raised because the drop-one single-sample estimate of shrinkage
is, in fact, an estimate of shrinkage. There is evidence that the
drop-one method provides inflated estimates of validation fit for the LSD
regression model when the population data is contaminated by extreme values,
e.g., populations 14 in Tables1, 2,
3, 4 .
In population 5 (Table 5) with 5% severe
contamination, both the LSD and LAD regression models provide estimates
of validation fit that are too high.
Acknowledgments. This study was supported by National Science
Grant ATM-9417563.
REFERENCES
Badescu, V., 1993: Use of Willmotts index of
agreement to the validation of meteorological models. Meteor. Mag.,122,
282286.
Barnston, A. G., and H. M. Van den Dool, 1993:
A degeneracy in cross-validated skill in regression-based forecasts. J.
Climate, 6, 963977.
Browne, M. W., 1970: A critical evaluation
of some reduced-rank regression procedures. Research Bulletin 70-21, Educational
Testing Service, Princeton, NJ.
, 1975a: Predictive validity of a linear
regression equation. Br. J. Math. Statist. Psychol.,28, 7987.
, 1975b: A comparison of single sample and
cross-validation methods for estimating the mean squared error of prediction
in multiple linear regression. Br. J. Math. Statist. Psychol., 28,
112120.
, and R. Cudeck, 1989: Single sample cross-validation
indices for covariance structures. Mult. Behav. Res., 24,
445455.
, and , 1992: Alternative ways of assessing
model fit. Sociol. Meth. Res., 21, 230258.
Camstra, A., and A. Boomsma, 1992: Cross-validation
in regression and covariance structure analysis. Soc. Meth. Res.,21,
89115.
Copas, J. B., 1983: Regression, prediction, and
shrinkage. J. Roy. Statist. Soc., 45B, 311354.
Cotton, W. R., G. Thompson, and P. W. Mielke, 1994:
Real-time mesoscale prediction on workstations. Bull. Amer. Meteor.
Soc., 75, 349362.
Efron, B., 1983: Estimating the error rate of a
prediction rule: Improvement on cross-validation. J. Amer. Statist.
Assoc., 78, 316331.
Elsner, J. B., and C. P. Schmertmann, 1993: Improving
extended- range seasonal predictions of intense Atlantic hurricane activity.
Wea.
Forecasting, 8, 345351.
, and , 1994: Assessing forecast skill through
cross-validation. Wea. Forecasting, 9, 619624.
Geisser, S., 1975: The predictive sample reuse
method with applications. J. Amer. Statist. Assoc., 70, 320328.
Glick, N., 1978: Additive estimators for probabilities
of correct classification. Pattern Recog.,10, 211222.
Gray, W. M., C. W. Landsea, P. W. Mielke, and K.
J. Berry, 1992: Predicting Atlantic seasonal hurricane activity 611 months
in advance. Wea. Forecasting, 7, 440455.
Hess, J. C., and J. B. Elsner, 1994: Extended-range
hindcasts of tropical-origin Atlantic hurricane activity. Geophys. Res.
Lett., 21, 365368.
Hora, S. C., and J. B. Wilcox, 1982: Estimation of
error rates in several-population discriminant analysis. J. Marketing
Res., 19, 5761.
Horst, P., 1966: Psychological Measurement and
Prediction. Wadsworth, 455 pp.
Huberty, C. J., J. M. Wisenbaker, and J. C. Smith,
1987: Assessing predictive accuracy in discriminant analysis. Mult.
Behav. Res., 22, 307329.
Kelly, F. P., T. H. Vonder Haar, and P. W. Mielke,
1989: Imagery randomized block analysis (IRBA) applied to the verification
of cloud edge detectors. J. Atmos. Oceanic Technol., 6, 671679.
Lachenbruch, P. A., 1967: An almost unbiased
method of obtaining confidence intervals for the probability of misclassification
in discriminant analysis. Biometrics,23, 639645.
, and M. R. Mickey, 1968: Estimation of
error rates in discriminant analysis. Technometrics,10, 111.
Lee, T. J., R. A. Pielke, and P. W. Mielke, 1995:
Modeling the clear- sky surface energy budget during FIFE 1987. J. Geophys.
Res., 100, 2558525593.
Livezey, R. E., A. G. Barnston, and B. K. Neumeister,
1990: Mixed analog/persistence prediction of seasonal mean temperatures
for the USA. Int. J. Climatol., 10, 329340.
MacCallum, R. C., M. Roznowski, C. M. Mar, and
J. V. Reith, 1994:Alternative strategies for cross-validation of covariance
structure models. Mult. Behav. Res.,29, 132.
Maltz, M. D., 1994: Deviating from the mean: The
declining significance of significance. J. Res. Crime Delinq., 31,
434463.
McCabe, G. J., and D. R. Legates, 1992: General-circulation
model simulations of winter and summer sea-level pressures over North America.
Int.
J. Climatol., 12, 815827.
Michaelsen, J., 1987: Cross-validation in statistical
climate forecast models. J. Climate Appl. Meteor., 26, 15891600.
Mielke, P. W., K. J. Berry, C. W. Landsea, and
W. M. Gray, 1996: Artificial skill and validation in meteorological forecasting.
Wea.
Forecasting, 11, 153169.
Mosier, C. I., 1951: Symposium: The need and means
of cross-validation, I. Problems and designs of cross-validation. Educ.
Psych. Meas., 11, 511.
Mosteller, F., and J. W. Tukey, 1977: Data
Analysis and Regression. Addison-Wesley, 586 pp.
Murphy, A. H., and R. L. Winkler, 1984: Probability
forecasting in meteorology. J. Amer. Statist. Assoc., 79,
489500.
Nicholls, N., 1985: Predictability of interannual
variations of Australian seasonal tropical cyclone activity. Mon. Wea.
Rev., 113, 11441149.
Picard, R. R., and R. D. Cook, 1984: Cross-validation
of regression models. J. Amer. Statist. Assoc., 79, 575583.
, and K. N. Berk, 1990: Data splitting. Amer.
Statist., 44, 140147.
Snee, R. D., 1977: Validation of regression models:
Methods and examples. Technometrics, 19, 415428.
Stone, M., 1974: Cross-validatory choice and assessment
of statistical predictions. J. Roy. Statist. Soc.,36B, 111147.
, 1978: Cross-validation: A review. Math.
Operationsforsch. Statist., Ser. Statistics, 9, 127139.
Subrahmanyam, M., 1972: A property of simple
least squares estimates. Sankhya, 34B, 355356.
Toussaint, G. T., 1974: Bibliography on estimation
of missclassification. IEEE Trans. Inf. Theory,20, 472479.
Tucker, D. F., P. W. Mielke, and E. R. Reiter,
1989: The verification of numerical models with multivariate randomized
block permutation procedures. Meteor. Atmos. Phys., 40, 181188.
Watterson, I. G., 1996: Nondimensional measures
of climate model performance. Int. J. Climatol.,16, 379391.
Willmott, C. J., 1982: Some comments on the evaluation
of model performance. Bull. Amer. Meteor. Soc., 63, 13091313.
, S. G. Ackleson, R. E. Davis, J. J. Feddema,
K. M. Klink, D. R. Legates, J. ODonnell, and C. M. Rowe, 1985: Statistics
for the evaluation and comparison of models. J. Geophys. Res., 90,
89959005.
*Current
affiliation: NOAA/AOML/Hurricane Research Division, Miami, Florida.
Corresponding
author address: Dr. Paul W. Mielke Jr., Department of Statistics, Colorado
State University, Fort
Collins, CO 80523-1877.
E-mail:
mielke@lamar.colostate.edu